
Research Workflow
Using LLMs for research · York University lecture, 2026
I run my cosmology analyses as large, reproducible computational pipelines — and I use language models as reviewers and engineering assistants within them, with every result verified and authored by me.
A short tour of how I work with these tools, and where I don't.
How I engage with these tools
Getting reliable work from a model whose behaviour shifts with the way you ask comes down to three habits: phrase and format deliberately, learn where the model fails, and hand the failing part to a tool that doesn't.
A language model places every word in a learned landscape, and the prompt decides where you start and which way you move. Phrasing is not cosmetic — in the models I tested for the 2026 lecture, two formats of the same question could shift its accuracy substantially — so I treat prompt design as part of the method.
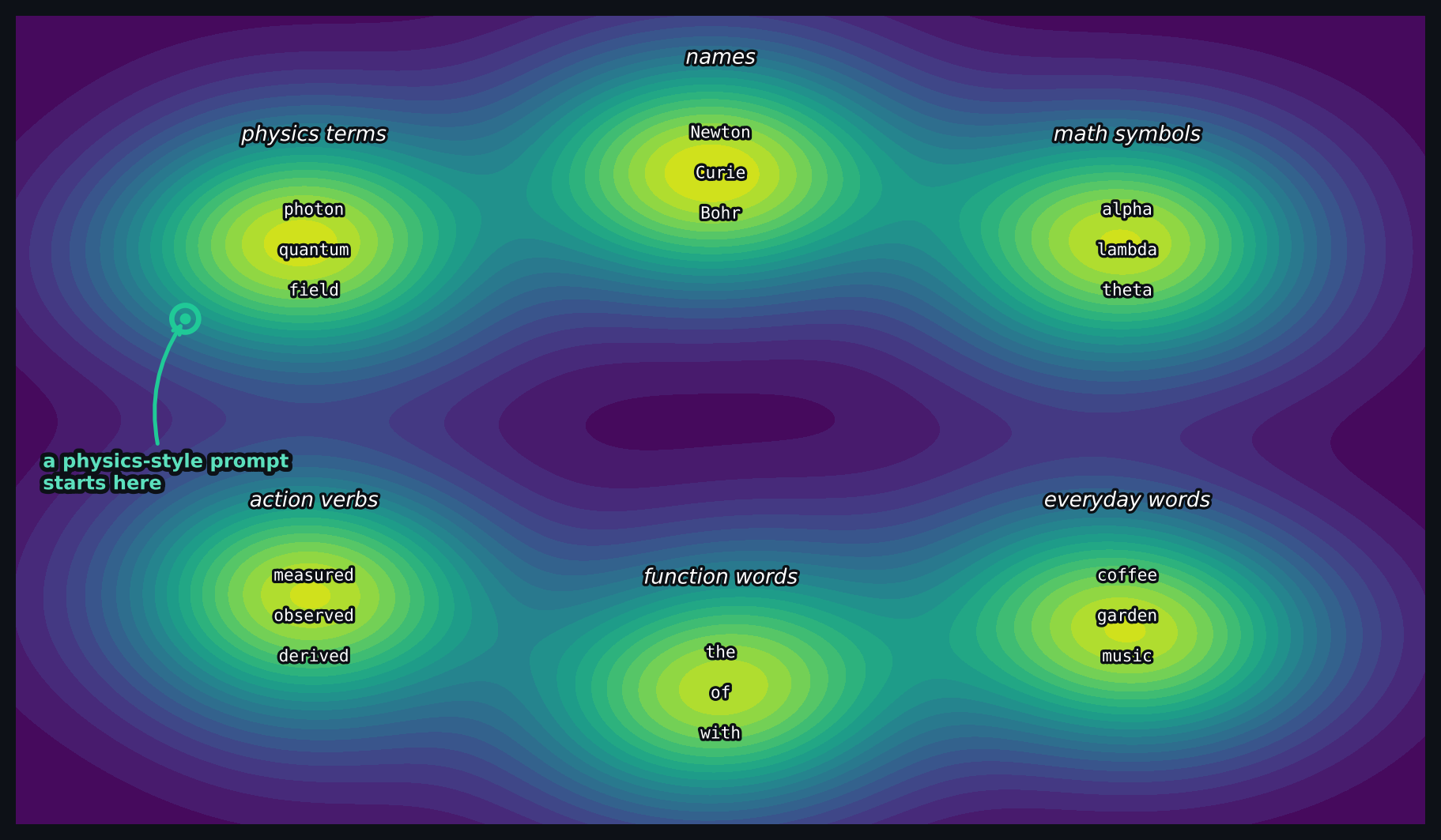
A sketch of the idea: related words cluster into regions, and the prompt sets where the model begins. Good prompting is steering within this landscape.
Most of a model’s well-documented failures — arithmetic, recall, rigid formatting, checking its own work — share one fix: stop asking the model to do the part it is bad at, and give it a tool that is good at it.
The workflow
A chatbot answers a message; an agent runs a loop — it plans, acts with tools, reads the result, and continues toward a goal it can check. Agents earn their keep exactly where research lives: multi-step work spanning code, notebooks, and writing, where every step can be verified.
I structure that loop the same way each time, and I keep planning and doing apart:
The model first reads the relevant code and reports its understanding back to me before touching anything; we agree a plan; only then does it write. Nothing important changes without that round-trip.
The useful artifact is not just the patch, but the audit trail around it: the files it read, the diff it produced, the tests or reruns that checked it, and the remaining assumptions I still have to inspect myself.
Every non-trivial change is then read by a panel of small, single-purpose reviewers, each with its own brief, whose findings a manager reconciles into one recommendation:
debugger
catches bugs and breaking changes after every edit
skeptic
scrutinises significant decisions; assumes hidden debt
conservator
flags unnecessary complexity; defends the working code
revolutionizer
asks whether a quick patch is hiding a deeper problem
tone · narrative
keep prose in my own voice and claims consistent across drafts
manager
reconciles the panel into a single, decisive recommendation
Finally, the project keeps its own memory: after a notable session the assistant records what was found and decided, and later sessions re-read it before starting. The reasoning accumulates across months instead of resetting with each new conversation. I keep sensitive or unpublished details out of tools unless I control where that context runs. (This website is maintained the same way.)
That boundary — work that loops and can be checked — is where I let them help, and where I don’t.
Using them with care
These tools amplify what you can do — and what you can get wrong; the faster one lets you move, the more discipline it takes. Five rules keep the science mine:
Used this way, the panel mostly catches the unglamorous errors that are easy to miss by eye — a formula or dimensional slip, a unit or sign convention, a configuration drifted out of sync — and pushes back when a conclusion outruns its evidence. The point is not speed; it is a higher standard, held consistently.
The lecture
I gave a lecture on this at York University in 2026 — first building intuition for how these models work, then walking through how I use them in day-to-day research.
Part I · how these models work
- next-token prediction as sampling from a learned distribution — and how a prompt reshapes it
- the sampling-temperature knob: order versus disorder, through a physicist's lens
- the well-documented failure modes — arithmetic, recall, formatting, self-checking, long-context drift
You leave able to read a model's behaviour, not just use it.
Part II · putting them to work
- agents versus chatbots, and the scope → plan → implement loop
- handing the failing part to a tool that doesn't — code, search, schemas
- review as a discipline: panels of differently-motivated checks
- persistent project memory and an auditable trail
- staying the author — where to rely on them, and where not to
You leave with a workflow you can run the next day.
The tools are genuinely useful today, and improving quickly — but long-horizon agents still drift, miss context, and need bounded tasks with external checks. The science stays mine: they change how carefully I can check it, not who is responsible for it.
Happy to share the lecture or slides — or to bring a version to your group or department.
Get in touch